Today we will be discussing “Capturing failures of large language models via human cognitive biases” by Jones and Steinhardt.
The rationality community is organized around trying to compensate for systematic biases in human thought. This movement was arguably started by “Thinking Fast and Slow” by Kahnemann and Tvarksy, and has reached its current state majorly through the writings of Eliezer Yudkowsky. Some common biases that humans have are the availability bias, anchoring effect, framing effect, etc. The authors of this paper decided to explore whether OpenAI’s Codex, which auto-completes code prompts as GPT-3 auto-completes word prompts, displays the same biases.
It does.
Note: The authors don’t just feed Codex random instructions, and then see what kinds of errors it makes. They essentially have a check-list of cognitive biases that they sequentially go down, and see if Codex is making those errors. Clearly this is not an exhaustive list of errors that Codex is making. In fact, it is possible that we discover a completely new type of error that Codex is making, test it on humans, and realize that humans make the same kind of error! This “inverse problem” is in fact an active field of research.
Framing bias
Framing bias is altering the choice of wording such that the same question, worded differently, seems different to you, thereby prompting a different response.

Here, the programmers write a completely unrelated prompt to influence the machine’s “thinking”, and then write the actual prompt they want turned into code. The machine thinks that all of the code is relevant.
What exactly should Codex ignore the previous part of the code? Aren’t those also instructions? I suppose Codex is designed to ignore previous functions.
Why is it important to include Codex’s own prompt in order to mislead it? Maybe this has something to do with the fact that humans work the same way: if you include their own input as part of the narrative, they attach more importance to it?
Anchoring effect
Anchoring effect is the process of altering one’s answer by pre-feeding it a possible answer.

Here, the correct answer is given in the darkened box on the right. However, just before Codex is asked for an answer, it is fed a modified version of the answer. Codex now gives that modified answer.
Availability heuristic
Availability heuristic is the bias in which we think that what we see more of around us is also more common in general. For example, a person living in a place where there are a lot of motorbike accidents might start thinking that motorbike deaths are a leading cause of death in the world, although that may be far from the truth.

Here, the program is being asked to compute 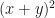
Attribute substitution
This is the bias where we substitute a required task with a different task that we are already trained to do (and often requires less work).

Codex is asked to define a function with a particular name. However, that name has already been fed to Codex as an entirely different function. Hence, that entirely different function is outputted instead of the required function.
High-impact errors
The authors use the study of these biases to predict the kinds of situations in which Codex would make costly errors, like deleting important files.

Codex is asked to remove the files that contain all four of statsmodels, plotly, seaborn and scipy. Codex, like every teenager (and non-teenager) ever that wants to cut corners, checks only for “statsmodels” instead of all four, and hence deletes more files than needed. This could of course prove to be a costly error if the erroneously deleted files were important.
Discussion
What does it mean for Codex to display the same biases as humans? Is it possible that humans are also ~12 billion parameter-neural networks? In some sense, that is entirely possible. We have billions of neurons, all of which have parameters that are slowly determined with time. Of course, we are not clean slates like neural networks are: we are born with a hard-coded propensity for language, for instance, that neural networks are not. But it is looking more and more possible that we are just self-replicating neural networks, and that artificial neural networks may soon be able to do the same. At least Metaculus thinks that.

